Nadine_J.S.
Signer mon livre d'or Faire connaître mon blog Me contacter par mail Flux RSS
Rechercher Derniers commentairesbonjour je m'appelle sammy kabwit je trouve trop génial votre aide vis-à-vis de moi même et de tout le monde.
Par Sammy Kabwit, le 28.05.2012
voilà c'est bien de formuler un site pareil à celuilà mais àa va etre mieu si vous laissez un espace de recher
Par soussou, le 24.09.2009
bonjour ami(e) blogueur(se)
je recherche des histoires ou anecdotes, amusantes, vraies, qui vous sont arri
Par vos-histoires, le 19.08.2009
bonsoir, je passe faire un tour de blog, donc le tient je le trouve trezs sympa et plein de gaieté et de bonne
Par robert, le 03.06.2009
· le mécanisme de pagination
· Différence entre FAT16-FAT32
· Mécanisme de pagination
· ACTIVE DIRECTORY
· Historique de Windows
Abonnement au blog
Statistiques
Date de création : 22.05.2009
Dernière mise à jour :
09.06.2009
5 articles
ACTIVE DIRECTORY
<!-- /* Font Definitions */ @font-face {font-family:"Cambria Math"; panose-1:2 4 5 3 5 4 6 3 2 4; mso-font-charset:0; mso-generic-font-family:roman; mso-font-pitch:variable; mso-font-signature:-1610611985 1107304683 0 0 159 0;} @font-face {font-family:Calibri; panose-1:2 15 5 2 2 2 4 3 2 4; mso-font-charset:0; mso-generic-font-family:swiss; mso-font-pitch:variable; mso-font-signature:-1610611985 1073750139 0 0 159 0;} @font-face {font-family:Algerian; panose-1:4 2 7 5 4 10 2 6 7 2; mso-font-charset:0; mso-generic-font-family:decorative; mso-font-pitch:variable; mso-font-signature:3 0 0 0 1 0;} /* Style Definitions */ p.MsoNormal, li.MsoNormal, div.MsoNormal {mso-style-unhide:no; mso-style-qformat:yes; mso-style-parent:""; margin-top:0cm; margin-right:0cm; margin-bottom:10.0pt; margin-left:0cm; line-height:115%; mso-pagination:widow-orphan; font-size:11.0pt; font-family:"Calibri","sans-serif"; mso-ascii-font-family:Calibri; mso-ascii-theme-font:minor-latin; mso-fareast-font-family:Calibri; mso-fareast-theme-font:minor-latin; mso-hansi-font-family:Calibri; mso-hansi-theme-font:minor-latin; mso-bidi-font-family:"Times New Roman"; mso-bidi-theme-font:minor-bidi; mso-fareast-language:EN-US;} p {mso-style-noshow:yes; mso-style-priority:99; mso-margin-top-alt:auto; margin-right:0cm; mso-margin-bottom-alt:auto; margin-left:0cm; mso-pagination:widow-orphan; font-size:12.0pt; font-family:"Times New Roman","serif"; mso-fareast-font-family:"Times New Roman";} p.MsoListParagraph, li.MsoListParagraph, div.MsoListParagraph {mso-style-priority:34; mso-style-unhide:no; mso-style-qformat:yes; margin-top:0cm; margin-right:0cm; margin-bottom:10.0pt; margin-left:36.0pt; mso-add-space:auto; line-height:115%; mso-pagination:widow-orphan; font-size:11.0pt; font-family:"Calibri","sans-serif"; mso-ascii-font-family:Calibri; mso-ascii-theme-font:minor-latin; mso-fareast-font-family:Calibri; mso-fareast-theme-font:minor-latin; mso-hansi-font-family:Calibri; mso-hansi-theme-font:minor-latin; mso-bidi-font-family:"Times New Roman"; mso-bidi-theme-font:minor-bidi; mso-fareast-language:EN-US;} p.MsoListParagraphCxSpFirst, li.MsoListParagraphCxSpFirst, div.MsoListParagraphCxSpFirst {mso-style-priority:34; mso-style-unhide:no; mso-style-qformat:yes; mso-style-type:export-only; margin-top:0cm; margin-right:0cm; margin-bottom:0cm; margin-left:36.0pt; margin-bottom:.0001pt; mso-add-space:auto; line-height:115%; mso-pagination:widow-orphan; font-size:11.0pt; font-family:"Calibri","sans-serif"; mso-ascii-font-family:Calibri; mso-ascii-theme-font:minor-latin; mso-fareast-font-family:Calibri; mso-fareast-theme-font:minor-latin; mso-hansi-font-family:Calibri; mso-hansi-theme-font:minor-latin; mso-bidi-font-family:"Times New Roman"; mso-bidi-theme-font:minor-bidi; mso-fareast-language:EN-US;} p.MsoListParagraphCxSpMiddle, li.MsoListParagraphCxSpMiddle, div.MsoListParagraphCxSpMiddle {mso-style-priority:34; mso-style-unhide:no; mso-style-qformat:yes; mso-style-type:export-only; margin-top:0cm; margin-right:0cm; margin-bottom:0cm; margin-left:36.0pt; margin-bottom:.0001pt; mso-add-space:auto; line-height:115%; mso-pagination:widow-orphan; font-size:11.0pt; font-family:"Calibri","sans-serif"; mso-ascii-font-family:Calibri; mso-ascii-theme-font:minor-latin; mso-fareast-font-family:Calibri; mso-fareast-theme-font:minor-latin; mso-hansi-font-family:Calibri; mso-hansi-theme-font:minor-latin; mso-bidi-font-family:"Times New Roman"; mso-bidi-theme-font:minor-bidi; mso-fareast-language:EN-US;} p.MsoListParagraphCxSpLast, li.MsoListParagraphCxSpLast, div.MsoListParagraphCxSpLast {mso-style-priority:34; mso-style-unhide:no; mso-style-qformat:yes; mso-style-type:export-only; margin-top:0cm; margin-right:0cm; margin-bottom:10.0pt; margin-left:36.0pt; mso-add-space:auto; line-height:115%; mso-pagination:widow-orphan; font-size:11.0pt; font-family:"Calibri","sans-serif"; mso-ascii-font-family:Calibri; mso-ascii-theme-font:minor-latin; mso-fareast-font-family:Calibri; mso-fareast-theme-font:minor-latin; mso-hansi-font-family:Calibri; mso-hansi-theme-font:minor-latin; mso-bidi-font-family:"Times New Roman"; mso-bidi-theme-font:minor-bidi; mso-fareast-language:EN-US;} .MsoChpDefault {mso-style-type:export-only; mso-default-props:yes; mso-ascii-font-family:Calibri; mso-ascii-theme-font:minor-latin; mso-fareast-font-family:Calibri; mso-fareast-theme-font:minor-latin; mso-hansi-font-family:Calibri; mso-hansi-theme-font:minor-latin; mso-bidi-font-family:"Times New Roman"; mso-bidi-theme-font:minor-bidi; mso-fareast-language:EN-US;} .MsoPapDefault {mso-style-type:export-only; margin-bottom:10.0pt; line-height:115%;} @page Section1 {size:612.0pt 792.0pt; margin:70.85pt 70.85pt 70.85pt 70.85pt; mso-header-margin:36.0pt; mso-footer-margin:36.0pt; mso-paper-source:0;} div.Section1 {page:Section1;} /* List Definitions */ @list l0 {mso-list-id:2064985789; mso-list-type:hybrid; mso-list-template-ids:90896416 67895311 67895321 67895323 67895311 67895321 67895323 67895311 67895321 67895323;} @list l0:level1 {mso-level-tab-stop:none; mso-level-number-position:left; text-indent:-18.0pt;} ol {margin-bottom:0cm;} ul {margin-bottom:0cm;} -->
Active directory
1. Principe et définition
C’est un service annuaire de Windows 2000, il permet de représenter et de stocker les éléments constitutifs du réseau informatique (données, utilisateurs, ordinateurs, bases de données, groupe, et stratégies de sécurité), sous forme d’un ensemble d’attributs appelés objets désignant un élément concret.
Ces objets sont organisés hiérarchiquement sous forme de schéma qui fait partir aussi de l’annuaire. Le service annuaire permet de mettre à la disposition de l’utilisateur ces informations ainsi qu’aux administrateurs ou applications selon le droit d’accès établi.
2. structure
Les objets d'Active Directory correspondent à des classes, c'est-à-dire des catégories d'objets possédant les mêmes attributs. Ainsi un objet est une « instanciation » d'une classe d'objet, c'est-à-dire un ensemble d'attributs avec des valeurs particulières.
Lorsqu'un objet contient d'autres objets, on le qualifie de conteneur. Les conteneurs permettent de regrouper les objets dans une optique d'organisation. A l'inverse si l'objet est au plus bas niveau de la hiérarchie, il est qualifié de feuille.
Historique de Windows
- 1981 de Dos à MS Dos
Dos est la première interface utilisateur et ancêtre de nos systèmes d'exploitation.Mais ne possède pas d'interface graphique.Son nom a changé et est allé à MS DOS.
- 1985 Windows1.0
Windows1.0 est lancé en 1985 et propose une corbeille,les menus déroulants,la superposition des fenêtres et leurs agrandissements.
La première version sortie est le1.01,ensuite le 1.02,ensuite1.03 qui prend en charge différents drivers européens comme le clavier Azerty.
- 1987-1992 De Windows2.0 à Windows3.1
Plus d'icônes cliquables, utilisation des applications telles que Word et Excell,superpositions des fénètres, améloiration de l'interfacegraphique.
le système utilise les processeur Intel et utilise la Ram pour allouer la mémoire.
La version 3.0(1990) a une interface améloiréé et puissante
la version 3.1(1992):propose des polices pour le traitement de texte.
- 1993.La famille NT(nouvelle technologie)
Partage d'impressions ou d'échanges de fichiers.Les données d'unordinateur sont accessibles aux autres machines lorsqu'ils sont en réseau et inclut aussi un gestionnaire de tâches.
Le système est multitâche,multi-utilisateur,multi-processeurs.
la version 3.1 augmente les compatibilités logicielles et matérielles.
La version 3.x est écrit en C por être compiler et fonctionner surdifférents processeurs malheureusement le code est volumineux pour s'exécuter.
- 1995.Windows 1995
INterface utilisateur travaillée, intégration de “mes documents” dans un nouvel explorateur de fichiers.
5versions de windows 95 sont sorties sur le marché windows95, windows95A, windows95B, windows95B USB, windows95C.
windows95 BUSB est le premier à prendre en charge le port USB et se vend dans certains pays de l'Europe sous le nom de windows1997.
- 1996.Windows NT40
ILutilise un environnement en 32 bits, reprend windows 95:les applications passent d'abord par l'interface de programmation qui aura pour rôle de les virtualiser.
- 1998.Windows98
Windows 98 est le premier système de Microsoft orienté vers un usage pour l'internet.Il possède Windows updates qui permet à tous les utilisateurs de garder leur système mis à jour à partir d'une connexion internet,Intégration de internet Explorer.
Meilleure exploitation des ports USB.possibilité de créer des partitions supèrieures à 2 GB.Il utilise le défragmentateur,le gestionnaire de tâches,un utilitaire de sauvegarde.Système de Fichier FAT32.
- 2000.wINDOWS 2000
Ce système est rapide, système de fichier FAT 32.cOMPATIBILIT2 DU MAT2RIEL SUR SES MACHINES PROFESSIONNELLES AVEC LE plug-and-play Et port firewire.
Nouveau gestionnaire de réseau .Connestions LAN, VPN, OU modem modifiables.La majorité des programmas fonctionnent sur Windows et les anti-virus peuvent être mise à jour
- 2000.Windows ME
Il se concentre sur les multimédia.Facilitation de l'importation des images,détecteur de scanners et appareils numériques.”Windows média player” pour suivre les vidéo ou musique et “Windows movie maker” pour éditer les films.
- 2001.Windows XP
Rassemble les fonctions de Millenium et de 2000 avec une interface graphique révue en profondeur .
Usage de Clear Type qui apporte un meilleur confort de lecture des caractères typographiques, l'accès Certains panneaux de l'explorateur autrefois inutiles sont reorganisés et avec un simple clic on peut par exemple accéder à “mes documents”.
Donne à l'ordinateur d'être multi-utilisateurs avec les comptes utilisateurs.A partir d'une autre machine on peut accéder au bureau ou au disque dur d'une machine.
Meilleure prise en charge des connections Internet MODEM et haut débit.Démocratisation de nouvelles technlogies.Plusieurs progammeS peuvent s'éxécuter.Microsoft developpe des applications.
Par la suite, Microsoft modifie XP afin de le rendre compatible avec certaines machines aux usages bien spécifiques.
Mécanisme de pagination
Principe de pagination :
- Les adresses mémoires émises par le processeur sont des adresses virtuelles, indiquant la position d'un mot dans la mémoire virtuelle.
- Cette mémoire virtuelle est formée de zones de même taille, appelées pages. Une adresse virtuelle est donc un couple (numéro de page, déplacement dans la page). La taille des pages est une puissance de deux, de façon à déterminer sans calcul le déplacement (10 bits de poids faible de l'adresse virtuelle pour des pages de 1 024 mots), et le numéro de page (les autres bits).
- La mémoire physique est également composée de zones de même taille, appelées « cases » (frames en anglais), dans lesquelles prennent place les pages.
- Un mécanisme de traduction (translation, ou génération d'adresse) assure la conversion des adresses virtuelles en adresses physiques, en consultant une table des pages » (page table en anglais) pour connaitre le numéro de la case qui contient la page recherchée. L'adresse physique obtenue est le couple (numéro de case, déplacement).
- Il peut y avoir plus de pages que de cases (c'est là tout l'intérêt) : les pages qui ne sont pas en mémoire sont stockées sur un autre support (disque), elles seront ramenées dans une case quand on en aura besoin.
Différence entre FAT16-FAT32
<!-- /* Font Definitions */ @font-face {font-family:"Cambria Math"; panose-1:2 4 5 3 5 4 6 3 2 4; mso-font-charset:1; mso-generic-font-family:roman; mso-font-format:other; mso-font-pitch:variable; mso-font-signature:0 0 0 0 0 0;} @font-face {font-family:Calibri; panose-1:2 15 5 2 2 2 4 3 2 4; mso-font-charset:0; mso-generic-font-family:swiss; mso-font-pitch:variable; mso-font-signature:-1610611985 1073750139 0 0 159 0;} /* Style Definitions */ p.MsoNormal, li.MsoNormal, div.MsoNormal {mso-style-unhide:no; mso-style-qformat:yes; mso-style-parent:""; margin-top:0cm; margin-right:0cm; margin-bottom:10.0pt; margin-left:0cm; line-height:115%; mso-pagination:widow-orphan; font-size:11.0pt; font-family:"Calibri","sans-serif"; mso-ascii-font-family:Calibri; mso-ascii-theme-font:minor-latin; mso-fareast-font-family:Calibri; mso-fareast-theme-font:minor-latin; mso-hansi-font-family:Calibri; mso-hansi-theme-font:minor-latin; mso-bidi-font-family:"Times New Roman"; mso-bidi-theme-font:minor-bidi; mso-fareast-language:EN-US;} p {mso-style-priority:99; mso-margin-top-alt:auto; margin-right:0cm; mso-margin-bottom-alt:auto; margin-left:0cm; mso-pagination:widow-orphan; font-size:12.0pt; font-family:"Times New Roman","serif"; mso-fareast-font-family:"Times New Roman";} .MsoChpDefault {mso-style-type:export-only; mso-default-props:yes; mso-ascii-font-family:Calibri; mso-ascii-theme-font:minor-latin; mso-fareast-font-family:Calibri; mso-fareast-theme-font:minor-latin; mso-hansi-font-family:Calibri; mso-hansi-theme-font:minor-latin; mso-bidi-font-family:"Times New Roman"; mso-bidi-theme-font:minor-bidi; mso-fareast-language:EN-US;} .MsoPapDefault {mso-style-type:export-only; margin-bottom:10.0pt; line-height:115%;} @page Section1 {size:595.3pt 841.9pt; margin:36.0pt 36.0pt 36.0pt 36.0pt; mso-header-margin:35.4pt; mso-footer-margin:35.4pt; mso-paper-source:0;} div.Section1 {page:Section1;} -->
FAT (File Allocation Table). Table d'allocation des fichiers qui décrit l'occupation d’un disque et l'endroit où s'y trouvent les fichiers. Le secteur du disque qui garde les adresses des fichiers s’appellent le Cluster et le FAT16 stocke les adresses des fichiers sur 16 bits. Avec l'augmentation de la capacité des disques, des adresses de 16 bits ne suffisaient plus. C'est pourquoi Microsoft a sorti la FAT32, avec des adresses sur 32 bits.
Tableau des différences en terme de taille par défaut des clusters
Dimension Drive | Default FAT16 Cluster Size Taille de cluster par défaut FAT16 | Default FAT32 Cluster Size Taille de cluster par défaut FAT32 |
260 MB–511 MB | 8 KB | Not supported Non prise en charge |
512 MB–1,023 MB | 16 KB | 4 KB |
1,024 MB–2 GB | 32 KB | 4 KB |
2 GB– 8GB | Not supported Non prise en charge | 4 KB |
8GB – 16GB | Not supported Non prise en charge | 8 KB |
16GB – 32GB | Not supported Non prise en charge | 16 KB |
> 32 GB | Not supported Non prise en charge | 32 KB |
le mécanisme de pagination
1 Le mécanisme de pagination
1.1. La pagination à un niveau
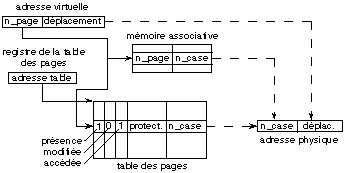
- L'indicateur de présence indique s'il y a une case allouée à cette page.
- Le numéro de case alloué à cette page.
- Les indicateurs de protection de la page indique les opérations autorisées sur cette page par le processus.
- L'indicateur de page accédée est positionné lors d'un accès quelconque.
- L'indicateur de page modifiée est positionné lors d'un accès en écriture.
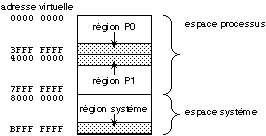
- La région système est commune à tous les processus. L'adresse de sa table de pages est une adresse de mémoire physique.
- Les régions P0 et P1 sont propres au processus, et leur table des pages est dans la région virtuelle système. L'adresse de leur table de pages respective est donc une adresse virtuelle. Les pages de la région P0 sont dans les adresses virtuelles basses, alors que celles de la région P1 sont dans les adresses virtuelles hautes. L'augmentation de la taille de la région P0 se fait donc vers les adresses virtuelles croissantes, alors que celle de la région P1 se fait vers les adresses décroissantes (figure 14.6).
1.2. La pagination à deux niveaux
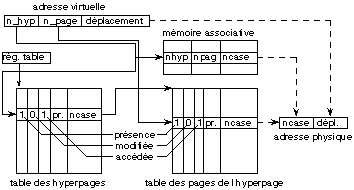
- L'IBM 370 dispose de plusieurs configurations possibles. Sur les machines à mémoire virtuelle sur 16 Moctets, on peut avoir, par exemple, 256 hypergages de 16 pages de 4096 octets.
- L'iAPX386 structure la mémoire virtuelle (appelée aussi mémoire linéaire lors de l'étude de la segmentation) en 1024 hyperpages de
1.3. La segmentation vis à vis de la pagination
- Avec la segmentation, le processus dispose d'un espace des adresses à deux dimensions que le processeur transforme en une adresse dans une mémoire linéaire. Sans la segmentation, le processus dispose directement de cette mémoire linéaire.
- Avec la pagination, on dispose d'une fonction de transformation dynamique des adresses de la mémoire linéaire en adresses de la mémoire physique, qui permet de placer les pages de la mémoire linéaire dans des cases quelconques de mémoire physique. Sans la pagination, les pages de la mémoire linéaire doivent être placées dans les cases de la mémoire physique de même numéro.
1.4. Le principe de la pagination à la demande
- L'algorithme optimal consiste à choisir la page qui sera accédée dans un avenir le plus lointain possible. Évidemment un tel algorithme n'est pas réalisable pratiquement, puisqu'il n'est pas possible de prévoir les accès futurs des processus. Il a surtout l'avantage de la comparaison: c'est en fait celui qui donnerait la meilleure efficacité.
- L'algorithme de fréquence d'utilisation (encore appelé LFU pour least frequently used) consiste à remplacer la page qui a été la moins fréquemment utilisée. Il faut maintenir une liste des numéros de page ordonnée par leur fréquence d'utilisation. Cette liste change lors de chaque accès mémoire, et doit donc être maintenue par le matériel.
- L'algorithme chronologique d'utilisation (encore appelé LRU pour least recently used) consiste à remplacer la page qui n'a pas été utilisée depuis le plus longtemps. Il faut maintenir une liste des numéros de pages ordonnée par leur dernier moment d'utilisation. Cette liste change lors de chaque accès mémoire, et doit donc être maintenue par le matériel.
- L'algorithme chronologique de chargement (encore appelé FIFO pour first in first out) consiste à remplacer la page qui est en mémoire depuis le plus longtemps. Sa mise en œuvre est simple, puisqu'il suffit d'avoir une file des numéros de pages dans l'ordre où elles ont été amenées en mémoire.
- L'algorithme aléatoire (encore appelé random) consiste à tirer au sort la page à remplacer. Sa mise en œuvre est simple, puisqu'il suffit d'utiliser une fonction comme random, qui est une fonction standard de presque tous les systèmes.
- L'algorithme de la seconde chance est dérivé de l'algorithme FIFO et utilise l'indicateur de page accédée. Lors d'un remplacement, si la dernière page de la file a son indicateur positionné, elle est mise en tête de file, et son indicateur est remis à zéro (on lui donne une seconde chance), et on recommence avec la nouvelle dernière, jusqu'à en trouver une qui ait un indicateur nul et qui est alors remplacée. Cela évite de remplacer des pages qui sont utilisées pendant de très longues périodes.
- L'algorithme de non récente utilisation (encore appelé NRU pour not recently used), est dérivé de LRU, et utilise les indicateurs de page accédée et de page modifiée de la table des pages, pour définir six catégories de pages (figure 14.8). Lorsque les pages sont dans les catégories C1 à C4, elles sont présentes dans la table des pages, et le matériel gérant les indicateurs peut les faire changer de catégories (transitions marquées * sur la figure). Lorsqu'elles sont dans les catégories C5 et C6, elles ne sont pas présentes dans les tables; un accès à une telle page provoquera donc un défaut de page. Périodiquement, le système transfère les pages des catégories C1 à C4 dans la catégorie qui est située immédiatement à droite sur la figure. De plus, il lance de temps en temps la réécriture sur mémoire secondaire de celles qui sont dans C5. Lorsqu'une telle réécriture est terminée, si la page est toujours dans C5, elle est transférée dans C6. Lorsqu'un défaut de page survient, le système recherche d'abord si la page demandée n'est pas dans C5 ou C6, pour la remettre alors dans la table, et ainsi la transférer dans C3 ou C4 suivant le cas (le matériel la mettra ensuite dans C1 ou C2). Si elle n'y est pas, il y a remplacement de la première page trouvée dans une catégorie, par numéro décroissant, c'est-à-dire, en commençant par C6.

On peut mesurer l'efficacité d'un algorithme de remplacement par la chance que la page soit présente en mémoire lors d'un accès, ou encore par la probabilité d'avoir un défaut de page lors d'un tel accès. On constate que les algorithmes se comportent presque tous assez bien et de la même façon. Évidemment l'algorithme optimal est le meilleur, suivi par les algorithmes LRU et LFU, ensuite par NRU et la seconde chance, et enfin par FIFO et aléatoire. Mais cette probabilité est beaucoup plus influencée par le nombre de cases attribuées à un processus que par l'algorithme lui-même.